BAGGING WITH RANDOM FOREST
Tổng quan¶
1. Giới thiệu¶
Random Forest là một trong những thuật toán học máy phổ biến và mạnh mẽ nhất. Nó là một loại thuật toán ensemble machine learning có tên là Bootstrap Aggregation (Bagging).
1.1 Bootstrap¶
Trước khi bắt đầu với thuật toán chính, ta xem xét một thuật toán nền tảng quan trọng đó là Bootstrap. Bootstrap là một phương pháp thống kê mạnh mẽ để ước tính số lượng từ một mẫu (sample) dữ liệu.
Giả sử ta có một mẫu gồm 100 giá trị $x$ và ta muốn lấy giá trị trung bình của mẫu đó. Ta có thể tính trực tiếp tư mẫu bằng công thức: $$\bar x=\frac{\sum x}{100}$$ Ta biết rằng mẫu của chúng ta là nhỏ và giá trị trung bình có sai sót. Chúng ta có thể cải thiện ước tính giá trị trung bình bằng cách sử dụng phương pháp Bootstrap như sau:
- Tạo nhiều mẫu phụ ngẫu nhiên (vd: 1000 mẫu) của tập dữ liệu (có thể chọn cùng một giá trị nhiều lần).
- Tính giá trị trung bình của từng mẫu phụ.
- Tính trung bình tất cả các giá trị trung bình thu thập được và lấy làm ước tính trung bình cho dữ liệu.
Ví dụ
Giả sử chúng ta có 3 mẫu và các giá trị trung bình từng mẫu lần lượt là 2.3, 4.5 và 3.3. Lấy trung bình của những giá trị này, ta được giá trị trung bình mới là 3.367.
1.2 Bootstrap Aggregation (Bagging)¶
Bootstrap Aggregation (Bagging), là một phương pháp kết hợp (ensemble) được thiết kế để tăng độ ổn định và chính xác cho thuật toán học máy. Đây là kỹ thuật kết hợp các dự đoán từ nhiều mô hình học máy khác nhau để đưa ra những dự đoán chính xác hơn bất kỳ mô hình riêng lẻ nào, có thể được sử dụng để giảm phương sai cho các thuật toán có phương sai cao và tránh tình trạng quá khớp (overfiting). Điển hình là cây quyết định (decision trees) thường được dùng cho phân loại (classification) và hồi quy (regression).
1.3 Random Forest¶
Random forest là sự cải tiến của bagging. Nó sử dụng các cây (tree) để làm nền tảng, là một tập hợp của hàng trăm cây quyết định, trong đó mỗi cây được tạo nên ngẫu nhiên từ việc tái chọn mẫu (chọn random 1 phần của dữ liệu để xây dựng) và random các đặc trưng (feature) từ toàn bộ dữ liệu.
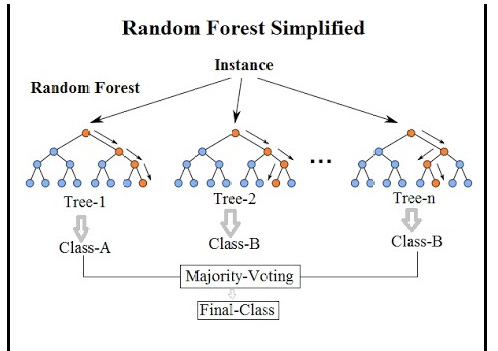 |
|---|
| Random Forest Simplified |
Để dễ hiểu hơn ta giả sử như Huyên muốn đi phẫu thuật thẩm mỹ, lúc này Huyên cần phải cân nhắc lựa chọn xem nên làm ở spa hay trung tâm nào. Để trả lời câu hỏi này, Huyên phải tham khảo ý kiến từ nhiều nguồn khác nhau như bạn bè, bộ phận tư vấn CSKH, internet, review. Mỗi một ý kiến đóng vai trò như một Cây quyết định trả lời các câu hỏi : Chỗ này có uy tín không? Chi phí như thế nào? CSKH có tốt không?…sau đó Huyên sẽ có một loạt các câu trả lời cho từng câu hỏi, từ đó quyết định phương án tốt nhất. Random Forest hoạt động bằng cách đánh giá các Cây quyết định sử dụng cách thức voting để đưa ra kết quả cuối cùng.
Random Forest là một phương pháp Supervised Learning, có thể xử lý được các bài toán về Classification (phân loại) và Regression (dự báo về các giá trị).
Thuật toán này được sử dụng trong rất nhiều lĩnh vực khác nhau, phổ biến là các ngành ngân hàng, dược phẩm, chứng khoán, và thương mại điện tử như : tìm kiếm khách hàng tiềm năng và khách hàng lừa đảo.
2. Ý tưởng chính¶
Giả sử ta có một tập huấn luyện $X=x_1,x_2,...,x_n$. Ta bagging nhiều lần ($B$ cây quyết định). Mỗi lần ta sẽ chọn ngẫu nhiên $m$ mẫu dữ liệu từ tập huấn luyện $X$. Và xây dựng các cây quyết định dựa trên $m$ mẫu dữ liệu này.
Sau khi đào tạo, các dự đoán cho các mẫu chưa nhìn thấy $x_i$ có thể được thực hiện bằng cách vote đa số trong các trường hợp. Quy trình bootstrapping này khiến hiệu suất mô hình tốt hơn vì nó làm giảm phương sai của mô hình, mà không làm tăng độ sai lệch (bias). Điều này có nghĩa là trong khi dự đoán của một cây rất nhạy cảm với nhiễu (noise) trong tập huấn luyện, thì trung bình của nhiều cây sẽ không bị ảnh hưởng, miễn là các cây không phụ thuộc vào nhau.
Số lượng mẫu $m$ của các tập huấn luyện cho mỗi cây quyết định $b$ và số cây $B$ là các hyperparameter. Thông thường, có một vài trăm đến vài nghìn cây được sử dụng, tùy thuộc vào kích thước và tính chất của tập huấn luyện. Có thể tìm thấy số lượng cây $B$ tối ưu bằng cách cross-validation), hoặc bằng cách quan sát out-of-bag error dự đoán trung bình trên mỗi mẫu đào tạo $x_i$.
3. Demo đơn giản¶
Vụ đắm tàu Titanic là một trong những vụ đắm tàu khét tiếng nhất trong lịch sử. Vào ngày 15 tháng 4 năm 1912, trong chuyến hành trình đầu tiên của mình, tàu RMS Titanic được coi là không thể tưởng tượng được đã bị chìm sau khi va chạm với một tảng băng trôi. Thật không may, số xuồng cứu sinh trên tàu không đủ cho tất cả mọi người trên tàu, dẫn đến cái chết của 1502 trong số 2224 hành khách và phi hành đoàn. Mặc dù có một số yếu tố may mắn liên quan đến việc sống sót, nhưng có vẻ như một số nhóm người có khả năng sống sót cao hơn những người khác.
Ở phần này ta sẽ thử sử dụng mô hình Random Forest để dựa đoán những loại người nào sẽ có khả năng sống sót cao. Ta sẽ sử dụng dữ liệu hành khách (tên, tuổi, giới tính, ...) được cung cấp ở trên Kaggle.
Các bạn có thê tải bộ data mình sử dụng để demo ở link sau: titanic3
import pandas as pd
df=pd.read_excel(r'titanic3.xls')
df.head()
Như ta thấy thì dữ liệu ta bao gồm rất nhiều các thuộc tính khác nhau. nhưng ở phần này ta chỉ sử dụng một số đặc trưng cơ bản như tuổi, giới tính, số người đi cùng (sibsp), số cha mẹ hoặc con cái đi cùng (parch) và tầng lớp kinh tế (pclass).
dataset=df[(['survived','pclass','sex','age','sibsp','parch'])]
dataset.head()
dataset.info()
Trước khi đi vào ta cần phải xử lý qua dữ liệu trước. Bước cơ bản là loại bỏ các điểm dữ liệu bị thiếu, format lại dữ liệu,...
dataset=dataset.dropna()
genders = {"male": 0, "female": 1}
dataset['sex']=dataset['sex'].map(genders)
dataset['age']=dataset['age'].astype(int)
dataset=dataset[dataset.age != 0]
dataset.info()
Như bao thuật toán khác thì ta sẽ tách dữ liệu thành hai phần gồm một để train và một để test.
from sklearn.model_selection import train_test_split
X = dataset[['pclass','sex','age','sibsp','parch']]
y = dataset[['survived']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
Ta sẽ sử dụng mô hình Decision Tree và Random Forest để so sánh độ hiệu quả của chúng.
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
acc_decision_tree = tree_model.score(X_test, y_test)
acc_decision_tree
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, y_train)
random_forest.score(X_train, y_train)
Như ta thấy thì kết quả đánh giá mô hình của Random Forest tốt hơn nhiều so với mô hình Decision Tree trên cùng một bộ dữ liệu train và test.
4. Kết luận¶
4.1 Ưu điểm¶
- Đây là thuật toán rất dễ để sử dụng, vô cùng mạnh mẽ, và linh hoạt.
- Giảm phương sai và tránh bị Overfitting.
- Random Forest có thể sử dụng cho cả bài toán Classification và Regression.
- Random Forest làm việc được với dữ liệu thiếu giá trị.
4.2 Nhược điểm¶
- Mất khả năng diễn giải của mô hình.
- Mặc dù Bagging cho chúng ta độ chính xác cao hơn, nhưng nó nặng về mặt tính toán và có thể không được như mong muốn tùy thuộc vào trường hợp sử dụng.
5. Tài liệu tham khảo¶
$^{[1]}$ Random Forest và ứng dụng
$^{[2]}$ Bootstrap aggregating
$^{[3]}$ Ensemble methods: bagging and random forests
$^{[4]}$ Random forest
$^{[5]}$ Bagging and Random Forest Ensemble Algorithms for Machine Learning